image
ConvNets Framwork.jpg
Primary tabs
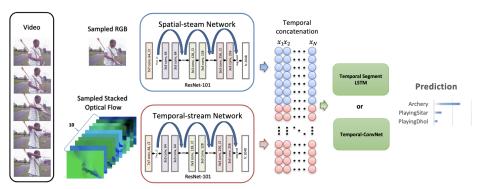
Overview of the proposed framework. Spatial and temporal features were extracted from a two-stream ConvNet using ResNet-101 pre-trained on ImageNet, and fine-tuned for single-frame activity prediction. Spatial and temporal features are concatenated and temporally-constructed into feature matrices. The constructed feature matrices are then used as input to both of our proposed methods: Temporal Segment LSTM (TS-LSTM) and Temporal-Inception.